我的服务器上不能没有Redis
安装Redis并且使用它!
Docker方式安装Redis
创建数据目录
创建一个目录存储数据和配置,我们要挂载到容器中
你完全可以跟着我命令一步一步走下去
cd ~
mkdir /opt/app/redis
mkdir /opt/app/redis/data
mkdir /opt/app/redis/conf
cd /opt/app/redis/conf
我们要从官网下载一份配置文件
wget -O redis.conf 'http://download.redis.io/redis-stable/redis.conf'
修改redis配置文件
vi redis.conf
注释掉bind 127.0.0.1 -::1 这个配置
/appendonly
修改 appendonly参数的值为yes 持久化数据
/requirepass
修改requirepass参数的值为 xxxxx 这是验证的密码
pull 镜像
docker pull redis
run起来
docker run -p 6379:6379 --name redis1 -v /opt/app/redis/data:/data -v /opt/app/redis/conf/redis.conf:/usr/local/redis/conf/redis.conf -d redis redis-server /usr/local/redis/conf/redis.conf
docker ps
可以看到有没有起来
如果没有起来 就使用命令查一下日志 看看是哪里出错了
docker logs 容器ID
如果按照上边来搞应该是没问题的.
远程连接
连不上的记得开放服务器的6379端口
下载客户端
https://github.com/qishibo/AnotherRedisDesktopManager/releases
https://gitee.com/qishibo/AnotherRedisDesktopManager/releases
网速不好选择用gitee来下载,下载exe结尾的安装下.
安装之后新建一个链接
Auth 是我们在redis.conf中配置的口令
然后链接!
既然装了Redis 就顺便复习一下旧知识 学习一下新知识
Redis的新数据类型
Geospatial(地理信息)
这个数据类型有点意思,字面翻译过来是地理信息 没错这个数据类型就是为了存储地理信息
经纬度是经度与纬度的合称组成一个坐标系统,称为地理坐标系统,它是一种利用三度空间的球面来定义地球上的空间的球面坐标系统,能够标示地球上的任何一个位置。
经纬度的有效范围为 经度 -180 度到 +180 度,纬度大约 -85 度到 +85 度。
geoadd
使用geoadd命令可以添加一条地理信息
geoadd key 经度 纬度 名称
//添加一条上海宝山区人民政府的地理信息
> geoadd china:shanghai 121.48941 31.40527 baoshan1
//添加一条上海宝山区友谊路地铁站的地理信息
> geoadd china:shanghai 121.47592 31.40393 youyilu
//添加一条上海浦东迪士尼乐园的地理信息
> geoadd china:shanghai 121.66035 31.14410 dishini
geopos
使用geopos命令获取一条地理信息
geopos key 名称
//获取我们刚刚存储的迪士尼地理信息
> geopos china:shanghai dishini
121.66035264730453491
31.14409987438899208
//可以看到上边获取的就是我们刚刚存储的经纬度信息
geodist
使用geodist命令可以获取两个地点之间的距离信息
geodist key 名称 名称 单位
//支持以下单位
m 表示单位为米[默认值]。
km 表示单位为千米。
mi 表示单位为英里。
ft 表示单位为英尺。
//获取宝山人民政府和友谊路的距离信息 单位米
> geodist china:shanghai baoshan1 youyilu
1289.4388
//获取宝山人民政府和迪士尼的距离信息 单位千米
geodist china:shanghai baoshan1 dishini km
33.2854
georadius
以给定经纬度为圆心找出半径内的地理信息
georadius key 精度 维度 半径 单位
//获取宝山区人民政府附近2km 的地理信息
//先获取宝山区人民政府的经纬度
> geopos china:shanghai baoshan1
121.48941010236740112
31.40526993848380499
//可以看到把我们上边的友谊路和宝山人民政府查找了出来
> georadius china:shanghai 121.48941010236740112 31.40526993848380499 2 km
youyilu
baoshan1
//扩大范围到100KM 就把迪士尼也查找了出来 应该是从最远距离列出的
georadius china:shanghai 121.48941010236740112 31.40526993848380499 100 km
dishini
youyilu
baoshan1
这玩意的应用场景很熟悉吧 一些社交软件的附近人功能 还有外卖软件的附近商家功能
Bitmaps(位图)
Bitmaps本身不是一种数据类型,实际上它就是字符串(key-value),但是它可以对字符串的位进行操作.
Bitmaps单独提供了一套命令,所以在Redis中使用Bitmaps和使用字符串的方式不太相同.可以吧Bitmaps想想成一个以位为单位的数组,数组的每个单元只能存储0和1,数组的下标在Bitmaps叫做偏移量.

这个东西说白了就是一串0101组成的字符串可以对每一位进行操作。
我们可以从业务角度去理解这个数据类型
假如部门要对部门的300名员工进行打卡考勤记录
0:未打卡 1:已打卡
setbit
设置bitMaps的偏移量
//我们来记录公共组十五位同事今天的打卡数据
//setbit key 偏移量(下标) value(0 or 1)
> setbit GGZ:daka:20210526 1 1
0
> setbit GGZ:daka:20210526 2 1
0
> setbit GGZ:daka:20210526 4 1
0
> setbit GGZ:daka:20210526 5 1
0
> setbit GGZ:daka:20210526 8 1
0
> setbit GGZ:daka:20210526 10 1
0
> setbit GGZ:daka:20210526 12 1
0
getbit
根据bitMaps的偏移量获取对应的值
//我们来获取id为10 和 11 的同事打卡数据
//getbit key 偏移量(下标)
> getbit GGZ:daka:20210526 10
1
> getbit GGZ:daka:20210526 11
0
//可以看到 id为10的同事打卡了 id为11的同事未打卡
bitcount
统计bitMaps中值为1的数量
//bitcount key
//我们来获取公共组今天打卡的数量计算出勤率
//可以看到 有7位同事打卡了 那么出勤率就是7/15=45%
> bitcount GGZ:daka:20210526
7
BitMaps的优势
bitMaps能做的其实其它集合类型也能做,无非就是保存key-value来记录数据.
但是他们之间占用的内存大小可是不一样的
| 数据类型 | 每个id占用空间 | 存储的用户量 | 内存占用量 |
|---|---|---|---|
| 集合 | 64位 | 50000000 | 64 * 50000000 / 8 = 400MB |
| BitMaps | 1位 | 100000000 | 100000000 / 8 = 12.5MB |
所以根据业务场景来选择数据类型是很有必要的。如果value值是这种 0 or 1 类型的,选用bitMaps肯定能大大节约内存的占用.
HyperLogLog(统计)
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
我们在了解基数的概念之后再来看这个数据类型。
基数说白了就是一堆数据中不重复的个数。
我们仍然是从业务角度来理解这个数据类型
假设我们有个网站每天有不同的人访问,每访问一次我们都记录下这个用户的IP地址
我们要统计这个次数可以这样来做
pfadd
//命令解释:pfadd key value 添加指定元素到 HyperLogLog 中
//记录今天访问9dtop网站的IP数据
> pfadd 9dtop:20210526 10.100.1.1
1
> pfadd 9dtop:20210526 10.100.1.2
1
> pfadd 9dtop:20210526 10.100.1.3
1
> pfadd 9dtop:20210526 10.100.1.1
0
> pfadd 9dtop:20210526 10.100.1.2
0
> pfadd 9dtop:20210526 10.100.1.4
1
> pfadd 9dtop:20210526 10.100.1.1
0
pfcount
//命令解释:pfcount key 计算HLL的近似基数
//计算今天访问9dtop的独立IP数量
> pfcount 9dtop:20210526
4
pfmerge
//命令解释:pfmerge newKey k1 k2 ... 将一个或多个HLL合并后的结果存储在另一个HLL中
//我们先模拟昨天的访问IP数据
> pfadd 9dtop:20210525 10.100.1.1
1
> pfadd 9dtop:20210525 10.100.1.2
1
> pfadd 9dtop:20210525 10.100.1.3
1
> pfadd 9dtop:20210525 10.100.1.4
1
> pfadd 9dtop:20210525 10.100.1.10
1
//现在我们要统计昨天和今天一共独立访问IP数量可以使用pfmerge命令
> pfmerge 9dtop:count 9dtop:20210525 9dtop:20210526
OK
> pfcount 9dtop:count
5
//可以看到两天独立IP近似基数的结果是5
可能会觉得,这种场景我们用set或者其它数据类型也可以统计
但是HLL占用内存少啊 要清楚的一点是,HLL并不存储相关的数据
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
如果有兴趣可以去了解下它的实现原理
HyperLogLog 算法的原理讲解
Redis中的事务
抛开那些概念用通俗的话来解释Redis中的事务
1.开启事务
2.命令排队
3.串行执行
通过一组命令顺序执行来干一件事情,这一组命令不会被其它命令打断
我们还是通过业务来理解
事务的用法
//从账户A向账户B转账200
//先创建两个账户
> set accountA 2000
OK
> set accountB 400
OK
//转账过程:账户A-200 账户B+200
//开启事务
> multi
OK
> decrby accountA 200
QUEUED
> incrby accountB 200
QUEUED
> exec
1800
600
//可以看到使用multi命令开启一个事务, 输入两条顺序执行的命令
//使用exec执行事务 这样就完成了一个事务的操作
事务的回滚
事务的基本特性其中有个原子性,要么都成功要么都不成功.
Redis的事务有点点奇怪~
我们先看看Redis的作者设计理念
Redis 作者认为基本只会出现在开发环境的编程错误其实在生产环境基本是不可能出现的(例如对 String 类型的数据库键执行 LPUSH 操作),所以他觉得没必要为了这事务回滚机制而改变 Redis 追求简单高效的设计主旨。
Redis中处理事务分两种情况
1.在事务开启之后命令排队阶段
你每次输入命令 它都会检查一下,如果你的语法有明显的错误 例如输入一个不存在的命令 或者输入set命令时只有key 没有value,Redis会返回错误信息到客户端,
并且在你exec执行这个事务的时候会被直接丢弃
2.在事务执行中阶段
当你把命令都输入到事务队列之后,没有检查出来语法错误 但是有一些隐藏的错误 例如对字符串类型的value值进行的incr操作. 在exec执行事务的时候,虽然到这个incr操作就会报错,但是还是会执行整个事务,只有这一条出错的没有被执行.也就是没有回滚操作.
用具体的操作来演示一下
//第一种情况
> multi
OK
> set test:A shanghai
QUEUED
> set test:B beijing
QUEUED
> niubi
(error) ERR unknown command `niubi`, with args beginning with:
> set test:C shenzhen
QUEUED
> exec
(error) EXECABORT Transaction discarded because of previous errors.
//第二种情况
> multi
OK
> set test:A shanghai
QUEUED
> set test:B beijing
QUEUED
> incr test:B
QUEUED
> set test:C shenzhen
QUEUED
> exec
1) OK
2) OK
3) (error) ERR value is not an integer or out of range
4) OK
//可以看到 第一种情况 事务直接被丢弃,第二种情况 只有错误的命令没有被执行
所以准确的说Redis的事务是原子性的, 第一种情况 都不执行,第二种情况都执行了,但是遇到错误了就没有回滚。因为Redis作者认为不应该出现这种情况。应该在测试环境就避免掉。或者熟练使用Redis命令就行~
调用 discard命令 会清空事务队列并退出事务
事务产生的问题
我们可以使用事务顺序执行一串命令且不被打断.但是我在执行命令的过程中,操作的Key是可以让所有人共享的.有可能我们事务执行完发现结果却不对~
还是拿上边两个转账的例子来说,accountA现在有1800块,accountB有600块。
我要让accountA把余额全都转给accountB,我可以开启一个事务保证一次执行不被打断.但是这个时候银行觉得你在洗钱,要没收你的财产(accountA-1800),这时候会出现什么情况?
//accountA操作转账给accountB
> multi
OK
> decrBy accountA 1800
QUEUED
> incrBy accountB 1800
QUEUED
>
//银行发现异常情况把accountA的余额清空掉
> get accountA
"1800"
> decrBy accountA 1800
(integer) 0
//accountA执行事务
> exec
1) (integer) -1800
2) (integer) 2400
//可以看到accountA账户-1800...并且转账给B成功了.
//这样肯定是不对的~ 如何解决?
Redis的作者就设计了一个(WATCH)看门狗,在开启事务之前,先监视要操作的Key,如果在你执行事务期间,这个Key发生变化了~那么这个事务就被丢弃不生效.
我们再看一遍上边的流程
//监视账户A
> watch accountA
OK
//accountA操作转账给accountB
> multi
OK
> decrBy accountA 1800
QUEUED
> set accountB 600
QUEUED
//银行发现异常,情况accountA的余额
> get accountA
"1800"
> decrBy accountA 1800
(integer) 0
//accountA执行事务
> exec
(nil)
> get accountA
"0"
> get accountB
"600"
可以看到,事务执行了,但是结果却是nil,accountA没有减 accountB也没有加!
这是怎么做到的?我们就看一下Redis事务中使用的锁机制
UNWATCH 可以解除对所有Key的监视
悲观锁&乐观锁
说起锁,就想起厕所~
我要上厕所,
我进去了把门上锁 你就进不来了
等我上完再把锁打开 你再进来把门上锁
如此循环就是悲观锁。
我要上厕所,
我进去了不上锁 你进来了看到了我 你就出去再等会
我上完了走了 你再进来上
如此循环就是乐观锁
我们来带入业务场景去理解,
现在有件商品库存是1,两个用户同时在购买
悲观锁
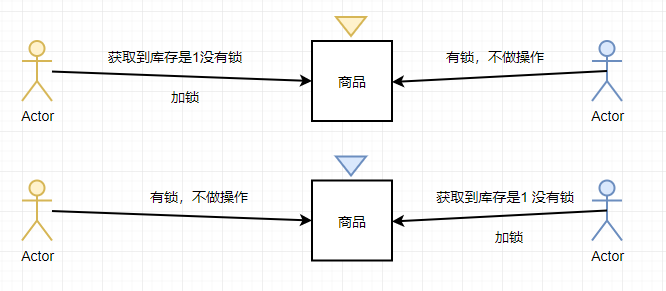
黄色用户去获取到库存之后,判断没有锁,就加了一把黄锁
这个时候蓝色用户获取到库存之后,判断有黄锁,就不做操作
然后黄色用户就可以成功购买这件商品。反之~
乐观锁
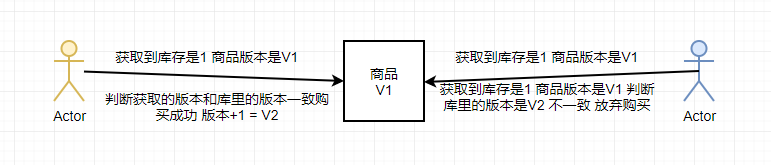
黄色用户和蓝色用户同时获取到了商品的版本是V1
黄色用户前一步判断自己拿到的版本号和库里边的版本号是一致的,那就购买并修改版本号为V2
蓝色用户判断当前的版本号V1不等于库里边的版本号V2 放弃购买。反之~
话说回来。Redis中的事务WATCH就是用了乐观锁。你都可以执行。但是执行前会判断你要操作的Key是不是已经变化了。变化了就执行失败~
你以为这样就完了?如果商品库存有100,同时有3000人并发访问,这个时候会出现什么情况?
假如3000人同时拿到了资源(商品的库存版本号为V1),其中有一个人跑得比较快(cpu调度) 反手一个购买,然后更改了商品的库存版本号为V2,这个时候其它2999个人比较之后,自己拿到的不是最新的库存,就放弃了~。这样就会导致 明明库存还有99,但是却只有一个人抢购成功. 那这个问题应该怎么解决呢,我们来看看LUA。
LAU脚本
Lua是一种功能强大,高效,轻量级,可嵌入的脚本语言
Lau脚本语法比较简单,有编程基础的应该是直接可以看懂Lau的代码。
我们看下边这段简单的lau代码,调用redis执行get命令,key是 KEYS[1], 判断取出的值是不是 ARGV[1] 如果是的话 那就删除这个Key
if redis.call('get', KEYS[1]) == ARGV[1]
then
return redis.call('del', KEYS[1])
else
return 0
end
在Java代码中使用Jedis的eval接口直接就可以执行这段lau代码,注意它是原子性的。
在我们认识了Lau脚本之后,就比较好解决上边的商品库存问题了。
编写一段Lau脚本,使获取库存-购买命令一起执行。这样就不会担心会出现的上边一系列问题,但是这个Lau脚本要想编写的没有瑕疵,不是那么容易的。
我们看一下Redis官方实现的脚本
//首先获取锁,可以用SET命令
//这串命令中 NX表示不存在Key的时候才能执行成功 PX指定Key过期时间为30000ms
SET 商品key 唯一标识 NX PX 30000
//解锁就是上边我们看到的那段lau代码
if redis.call('get', KEYS[1]) == ARGV[1]
then
return redis.call('del', KEYS[1])
else
return 0
end
因为以前的redis set命令并不支持原子操作
加锁需要 先setNX 然后再赋过期值,
新版本的set命令 支持原子操作,所以就没必要用lau脚本了。
可以看一下中文站翻译的官方文档
Redis分布式锁
其实按照上边这些步骤走下来,单机使用应该是没有大的问题,但是生产环境还是有很大的问题.有兴趣可以看一下redisson是如何使用redis来实现分布式锁的。
这一篇就写的挺不错 推荐看看~
Redission实现分布式锁完美方案
剩下的主从、哨兵、RDB、AOF之类的就不去复习了
真正用到的时候全靠强大的搜索引擎,不是看一遍读一遍就能记住的。
主要是在这里了解下Redis的新数据类型和以前没接触过的分布式锁。